Programmatic incidents
When a monitor detects trouble (respecting your confirmation settings and any keyword/SSL checks), Phare springs into action by creating an incident. Each incident is automatically linked to the affected monitor and includes detailed information about what went wrong. Right away, alert recipients are notified through your configured alert rules, no manual intervention required. Programmatic incidents track the entire lifecycle from detection through resolution, giving you a complete picture of what happened during the outage.Manual incidents
Sometimes you need to create an incident even when your monitors haven’t detected a problem. Perhaps a customer reported an issue with a service you’re not actively monitoring, or you want to proactively communicate about planned maintenance. Phare makes it easy to create incidents manually:- Select the affected monitor(s)
- Set the impact level
- Add a descriptive title
- Include details about the situation
Incident recovery
When your service recovers (again, respecting your recovery confirmation settings), Phare automatically resolves the incident and notifies recipients through your alert rules.Impact
Not all incidents are created equal. That’s why Phare lets you classify incidents by their impact level:- Unknown: Still investigating, not sure how bad it is
- Operational: False alarm. Everything’s working as expected
- Maintenance: Planned downtime for heavy-duty updates
- Degraded performance: Things are slower / working less well than usual
- Partial outage: Some users are affected or certain features are down
- Major outage: Everything is on fire, users can’t access the service or are severely impacted
Event timeline
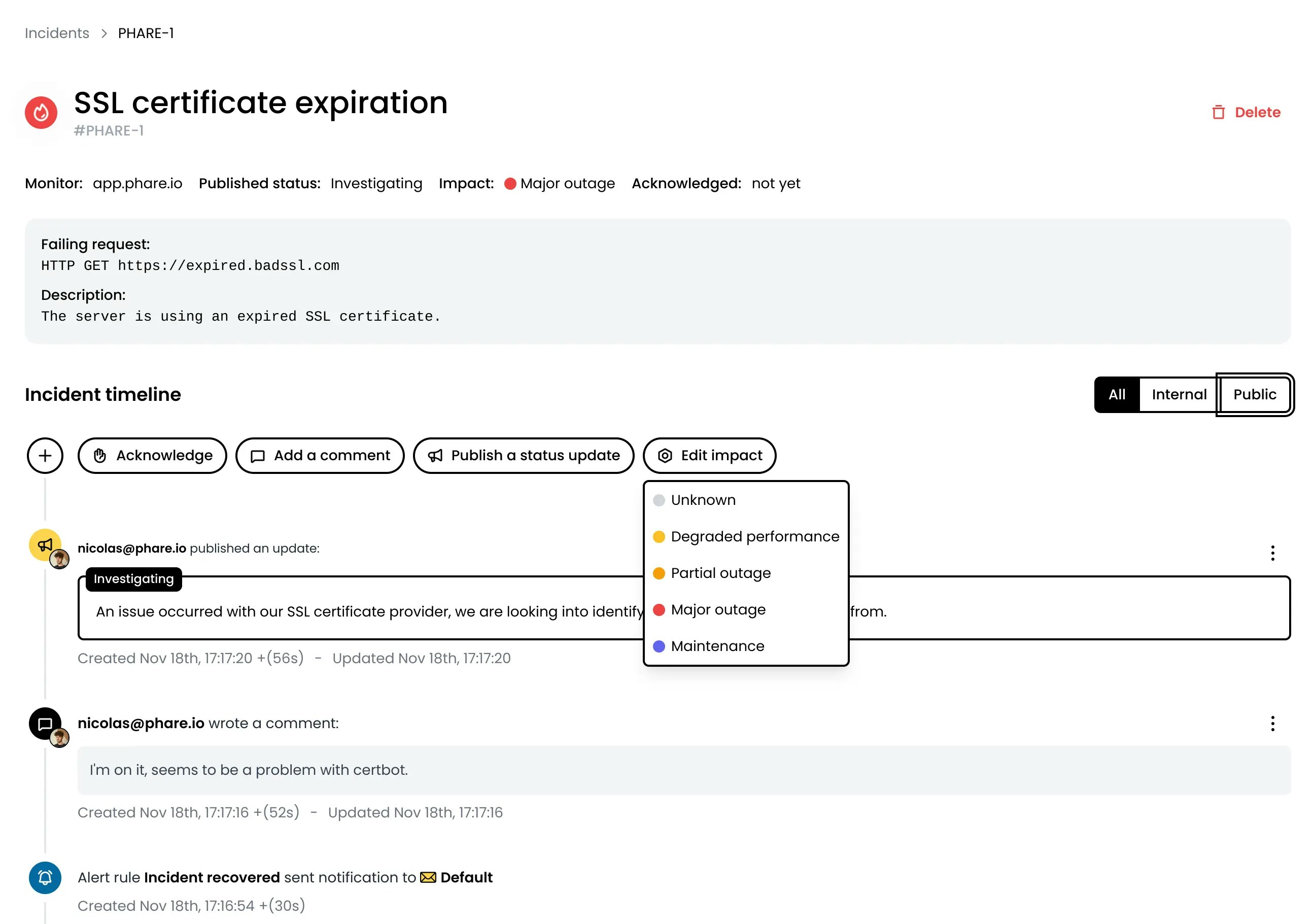
Incident comments
Team members can add private comments to share insights or document solutions, helping everyone resolve issues faster. These internal notes are perfect for:- Documenting troubleshooting steps
- Sharing relevant links to logs or dashboards
- Coordinating response efforts between team members
- Recording root cause analysis findings
Incident updates
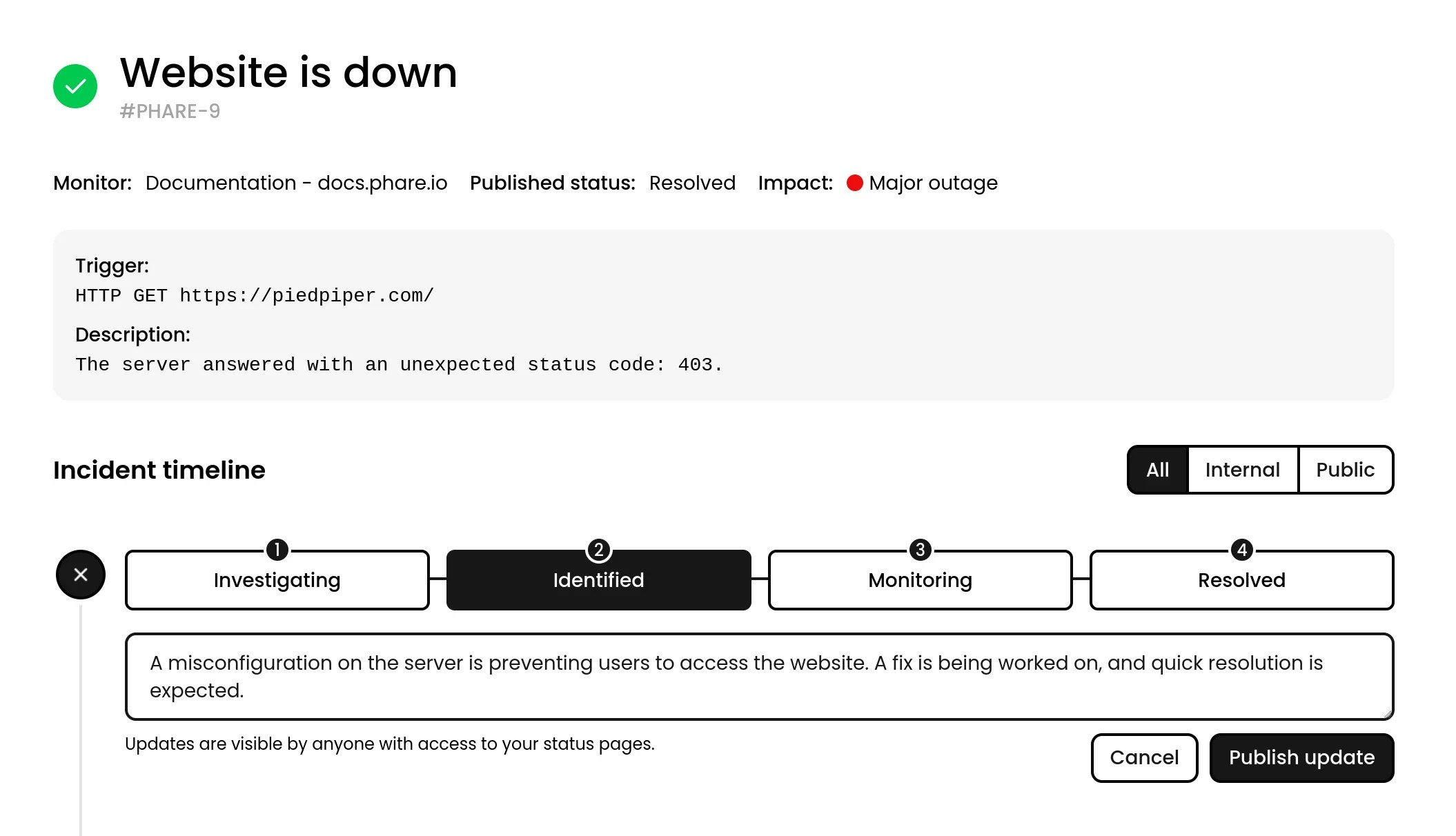
- What’s happening with the incident
- What you’re doing to fix it
- When they can expect resolution
- Workarounds they can use in the meantime
Smart incident merging
Smart incident merging reduces noise by grouping multiple, similar failures into a single incident that evolves over time. Instead of opening a new incident for every affected monitor, Phare can merge them together, keep one timeline, and notify recipients more intelligently.Configuration
Smart incident merging can be configured per-project, allowing you to tailor the behavior to different services or groups. You can also set a preferred time window for merging, balancing responsiveness with noise reduction.
Start with a moderate window of 10 to 30 minutes. If you often experience bursty or cascading failures, a longer window will reduce duplicate incidents further.
How it works
Only incidents belonging to the same project can be merged together. When a new incident is created, even before confirmation, Phare checks for any existing open incidents in the project that share the same reported issue. If it finds one within the configured time window, it merges the new incident into the existing one. This approach, even though simple, provides fast and reliable results for most incident scenarios.Dedicated alert rule events
Two alert rule events are available to help you react precisely to incident propagation and partial recoveries: Paired with notification threads on the Email, Discord, or Slack integrations, notifications stay focused: one creation, threaded follow‑ups for expansions and partial recoveries, and a final recovery when everything is back to normal.Incident AI
Incident AI leverages the Mistral AI platform to analyze incident data and generate useful summaries and post-mortem reports. By understanding the context and details of each incident, Incident AI helps resolve issues faster and improve future response strategies. This feature is powered by Mistral Small 4, a lightweight model that provide fast reasoning with lower costs and energy use.Configuration
Incident AI can be activated per-project, allowing compliance with different data policies across your organization.
How it works
When activated, Phare will automatically generate an AI incident summary when an automated incident is created, and a post-mortem report when it is resolved. Incident AI is not active on manually created incidents. Each AI generation consumes one credit from your plan’s monthly allowance. When the quota is exhausted, no further AI generation is performed until the next billing cycle. Additional quota can be configured if your organization is subscribed to the Scale plan.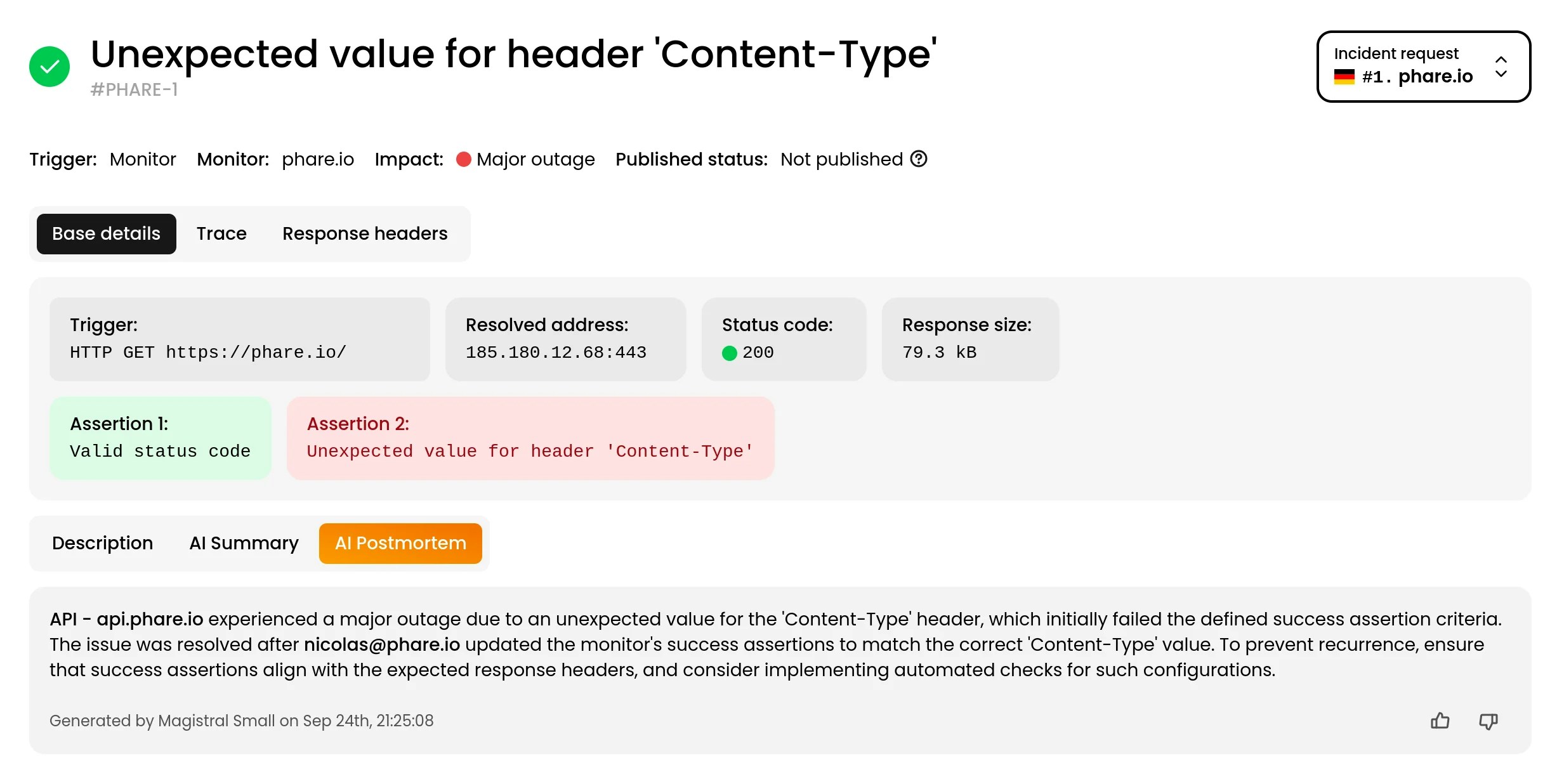
Incident AI is in its early stages and may not always produce perfect results. Carefully review AI-generated content before sharing it with users.
Privacy
To protect your data, Incident AI only processes strictly necessary information related to the incident, such as:- Incident data
- Impacted monitors
- Failed request responses
- Incident event timeline
- Incident comments
- Incident updates